TLP(Thread-Level Parallelism)¶
约 3752 个字 9 行代码 11 张图片 预计阅读时间 19 分钟
我们在之前学习了两种并行方式:
-
ILP(Instruction-Level Parallelism): 指令级并行性
-
在单个处理器中并行执行多条指令
-
依赖硬件进行指令调度(流水线、乱序执行、超标量等)。
-
-
DLP(Data-Level Parallelism): 数据级并行性
-
对多个数据进行同样的操作
-
比如:对一个数组中的每个元素加1,是完全的数据级并行操作。
-
通过架构设计(SIMD、Vector等)来实现。
-
而在这里我们介绍的是TLP(Thread-Level Parallelism): 线程级并行性。
TLP使用MIMD(Multiple Instruction Multiple Data)架构,每个处理器抓取不同的指令,并对不同的数据进行操作。
这之中需要用到多处理器(Multiple Processors),主要有两种:
-
多核处理器: 在单个芯片上集成多个处理器核心。
-
多处理器系统: 在多个芯片上集成多个处理器。
Multiprocessor Architecture¶
根据内存的组织与互联策略,将多处理器架构分为如下两种
-
Symmetric/Centralized Shared Memory (SMP/CSM): 对称/集中式共享内存
-
所有处理器共享同一物理内存。
-
比较常用
-
32个核或更少
-
所有处理器访问内存的延迟是均一的,因此SMP也被称为Uniform Memory Access (UMA)。
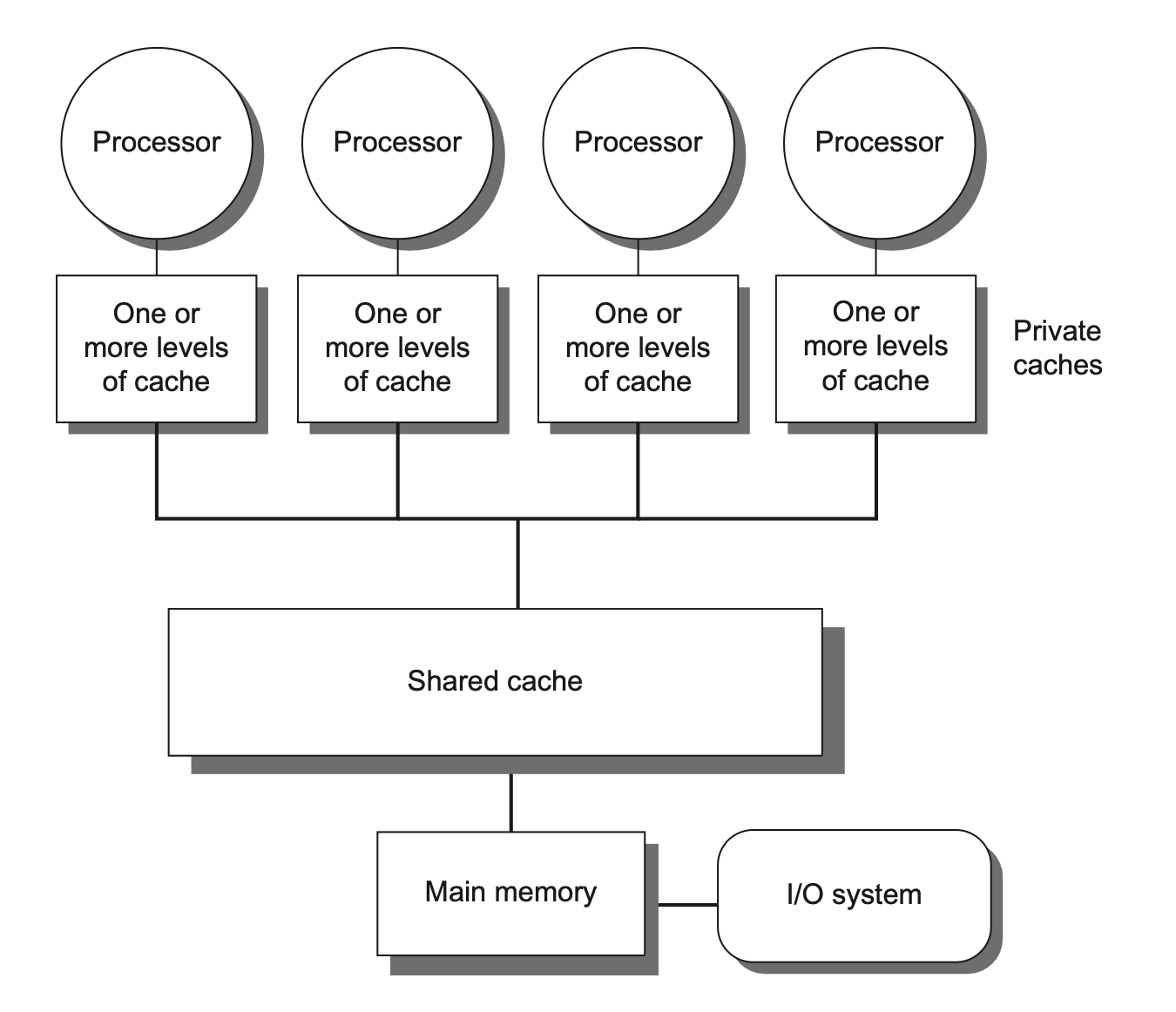
-
-
Distributed Shared Memory (DSM): 分布式共享内存
-
每个处理器有自己的本地内存。
-
通过网络连接实现内存的分布式访问。
-
本地内存访问快,但是远程内存访问就很慢了,NUMA(non-uniform memory access)架构。
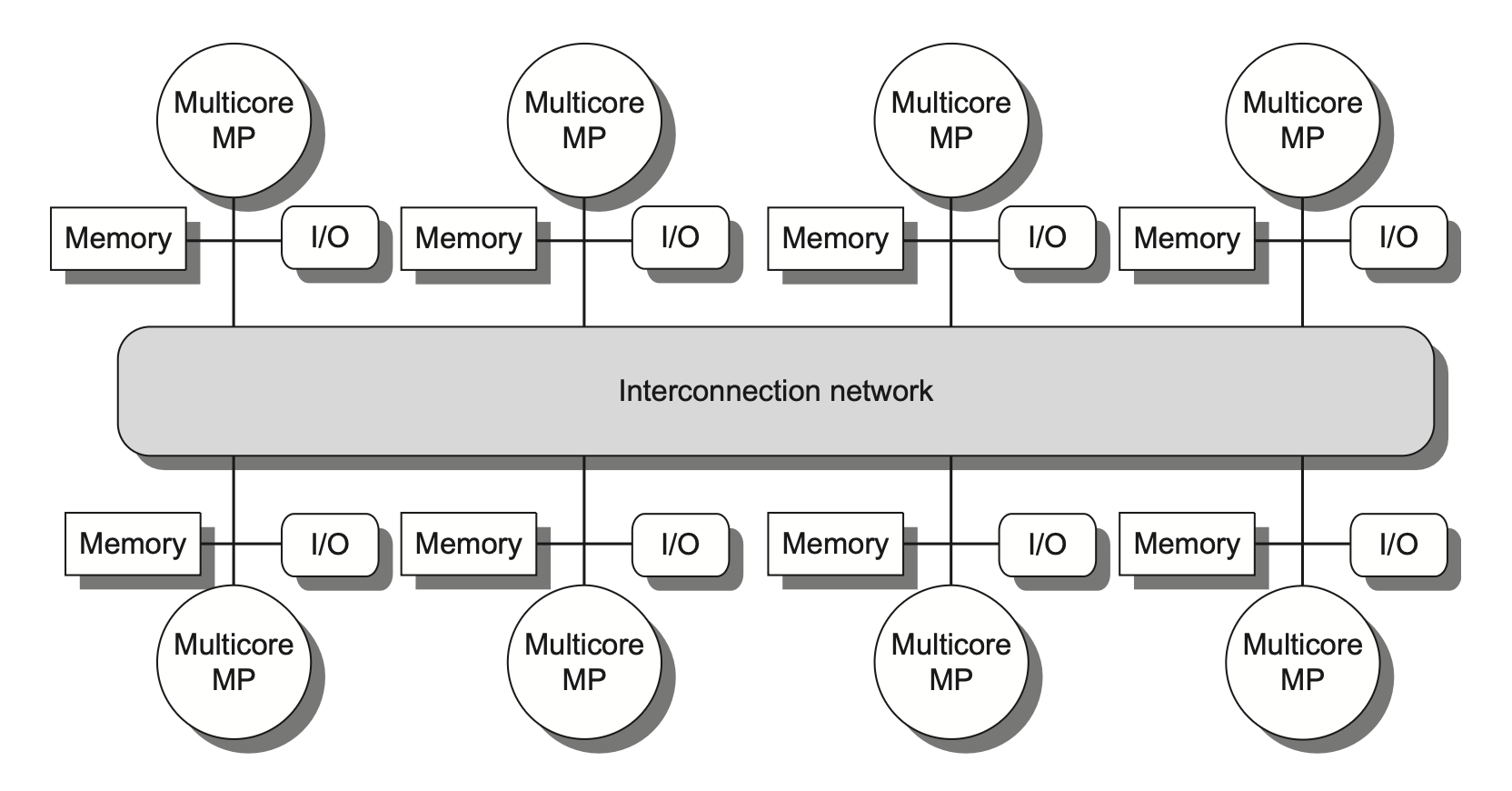
- DSM需要更复杂的处理器通信,以及更复杂的软件来处理分布内存
-
Hundles of Parallel Processing¶
主要有两个问题:
-
程序本身并行性不强
-
多处理器之间的通信开销大
这两个问题会导致多处理器的性能提升不明显。
Limited Program Parallelism¶
Example
要实现A+B+2的计算:
后面的并行程度就大于前面的
再回到前面说过的Amdahl's Law:
为了在一百个处理器下达到80倍的加速,串行部分的比例是多少?
所以,需要串行部分占如此少,才能在100个处理器下达到80倍的加速。
如果要优化的话,需要:
-
设计能提供更优并行性能的算法
-
设计软件系统,让处理器全负荷运转下的有效执行时间延长
Communication Overhead¶
通信开销包括了并行处理器中远程访问的高延迟
Example
一个app跑在一个32处理器的MP上,处理器访问远程内存需要100ns.
处理器时钟频率4GHz,基础CPI为0.5
那么,没有任何通信的情况下,比0.2%指令访问远程内存,快了多少?
Tip
假设一共N条指令
-
没有通信情况下,需要\(N \times 0.5 = \frac{N}{2}\)周期
-
在需要远程访问的情况下,远程访问一次内存需要\(100 \times 10^{-9} \times 4 \times 10^9 = 400\)周期
- 那么,一共需要\(N \times 0.5 + 0.2 \% \times 400 \times N = 1.3N\)周期
-
因此快了2.6倍
-
所以,仅仅是占比如此少的远程内存访问就带来了如此大的延迟
要优化的话,需要使用Cache,预取等技术来减少远程访问。
Centralized Shared Memory¶
如该图所示:
每个处理器都有自己的Cache,并且通过总线连接到共享内存。
当这样的设计带来了一个新的问题.为了保证高速,我们肯定是希望每个处理器尽量少通信,多使用自己的Cache,然而,当一个处理器在自己的Cache里修改了数据后,如果它的Cache和其他处理器的Cache之间没有同步,那么其他处理器就会读取到过时的数据。
这就是Cache Coherence问题。
我们定义,一个内存系统是一致的(Coherent)的,当对任何数据项的读取都返回这个数据项最近写入的值
有两个容易混淆的概念:Coherence和Consistency
-
Coherence: 决定了读取操作可以返回什么值
-
Consistency: 决定写入的值什么时候可以被读操作返回
Coherence Property
-
处理器 P 对位置 X 执行写操作后,如果紧接着对 X 执行读操作,且在此期间没有其他处理器对 X 进行写入,那么该读操作必须返回 P 刚才写入的值。
-
当处理器 A 对位置 X 的读操作发生在处理器 B 对 X 的写操作之后,只要读写操作之间有足够的时间间隔,且期间没有其他对 X 的写操作,那么 A 的读操作应该返回 B 写入的值。
-
写串行化(write serialization): 对同一位置 X 的所有写入操作在任一处理器看来,都是按照它们的时间顺序发生的。比如,如果一个位置先被写1,再被写2,那么处理器看到的不能是先写2再写1。
满足上述三个性质,我们就能确保一致性.然而,对于Consistency,比如A在B写后马上读取,这时是很有可能读到错误的值的,这时就需要锁.
Cache Coherence Protocols¶
Cache Coherence Protocols是用来确保多个处理器的Cache之间数据一致性的协议。
有两种方法:
-
Directory-Based Protocols: 目录式协议
-
使用一个中心目录来跟踪每个数据块的状态和所在的Cache。
-
当处理器需要访问数据时,它会查询目录以获取最新状态。
-
优点是可以减少通信开销,缺点是需要额外的存储空间来维护目录。
-
-
Snooping Protocols: 监听协议
-
每个处理器的Cache会监听总线上的所有读写操作。
-
当一个处理器写入数据时,其他处理器可以通过监听到这个操作来更新自己的Cache。
-
优点是实现简单,缺点是随着处理器数量增加,总线通信开销也会增加。
-
Snooping Protocols¶
有两种Snooping Protocols:
-
Write-Invalidate:当一个处理器对某个数据项写之后,它在总线上放一个
invalidate信号,其他处理器收到这个信号后,就会将自己的Cache中对应的数据项标记为无效。这样,如果尝试访问这个数据项,就会直接Cache Miss,然后从主存中重新加载。
-
可以看到,在A写了之后,B里面的数据直接没了
-
如果一个处理器接受到的invalidate信号是它的Cache中的脏数据,那么它必须先将这个脏数据写回到下一级Cache,然后再将当前Cache中的数据标记为无效。
-
-
Write-Update:当一个处理器对某个数据项写之后,它会将这个数据项的最新值广播到总线上,其他处理器收到这个信号后,就会更新自己的Cache中对应的数据项。(通信量大,一般较少用)
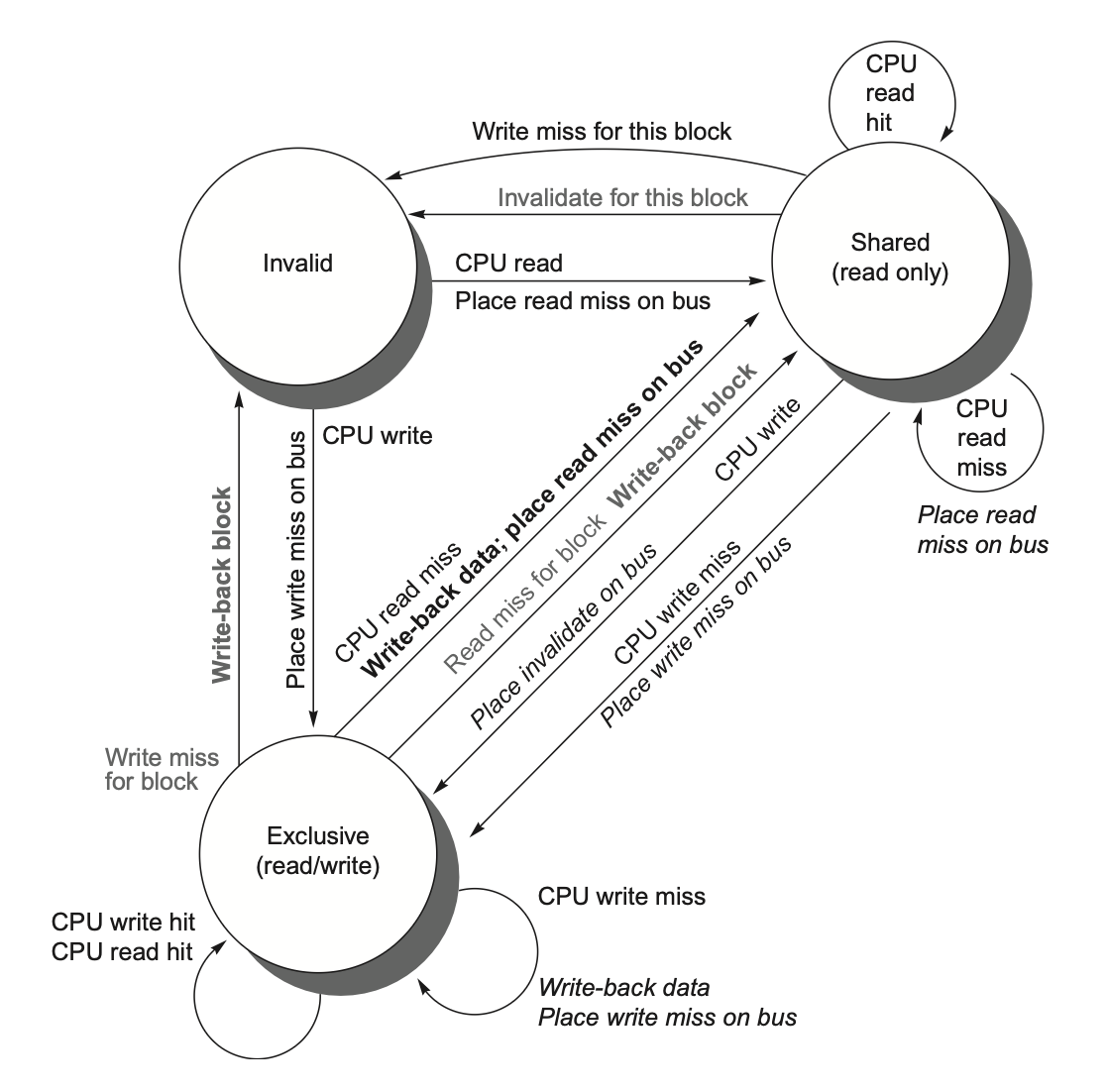
上面都是概念上的协议.在具体实现中,通常使用有限状态机,下面是一些具体的协议实现:
-
MSI Protocol,数据块有三种状态:
-
Modified: 数据项在当前Cache中被修改,且其他Cache中没有这个数据项的副本(或被无效),类似于排他锁
-
Shared: 数据项在当前Cache中未被修改,且可能在其他Cache中有副本。通常是多个处理器读取同一数据项时的状态,类似于共享锁
-
Invalid: 数据项在当前Cache中无效。
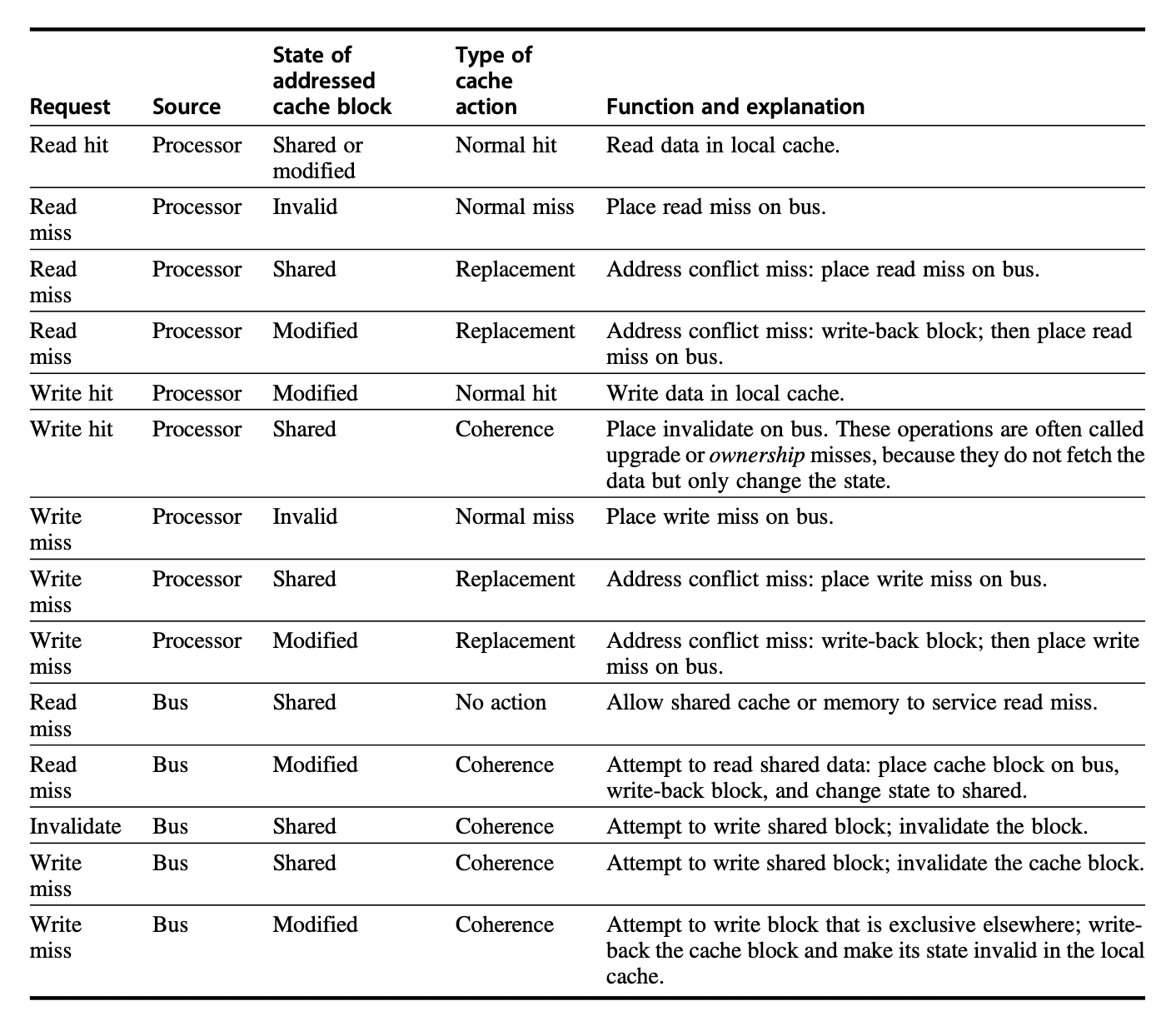
不同情况下的处理,来自bus的请求意味着其他处理器要访问本处理器中的数据项- 根据请求来源导致的状态转变,有如下状态机:
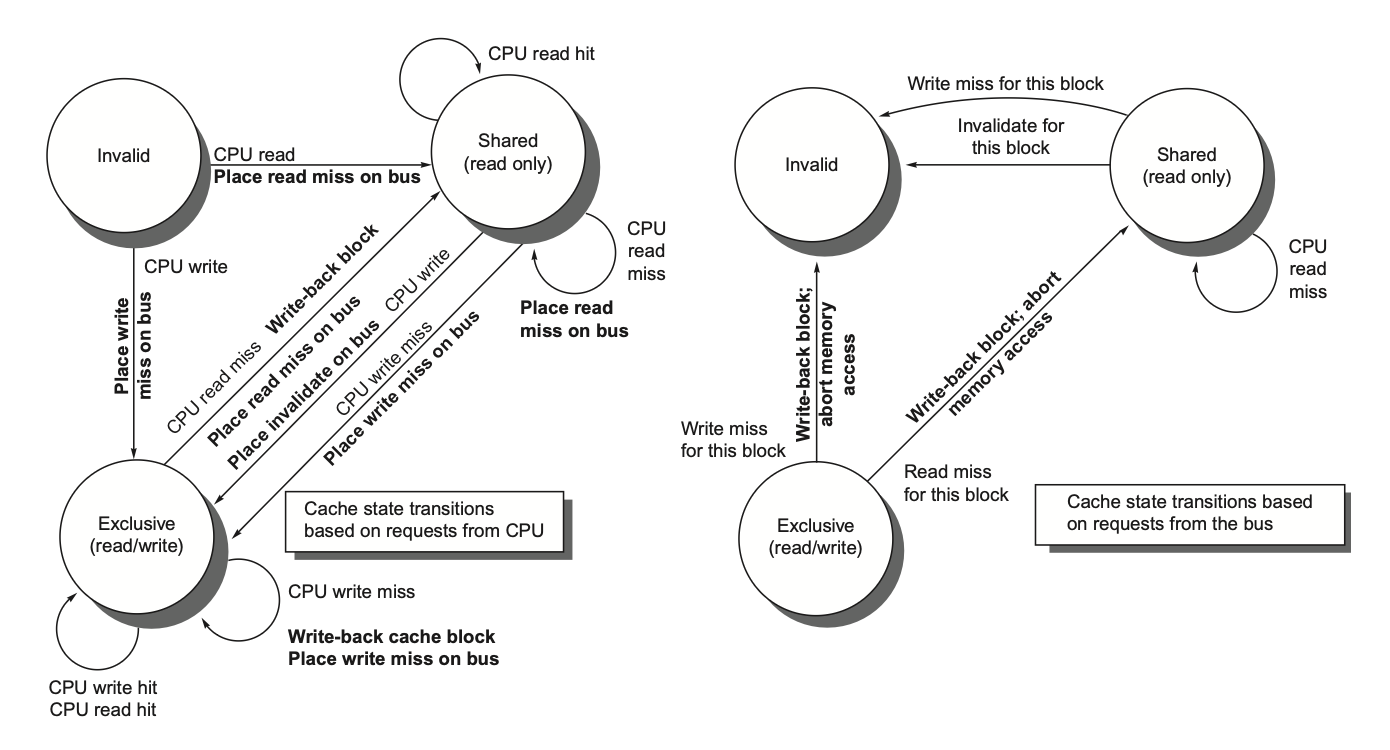
- 汇总:
-
-
MESI Protocol,在MSI的基础上增加了一个状态:
-
Exclusive: 数据项在当前Cache中未被修改,且其他Cache中没有这个数据项的副本。也即,这个数据项仅在当前CPU的Cache中存在,且不是脏的。
-
在这个状态下:
-
如果其他CPU读取了这个数据项,则从Exclusive变为Shared
-
如果自己修改了这个数据项,则从Exclusive变为Modified
-
-
这样,有可能写了一个数据项,但不需要发出invalidate信号,减少开销
-
-
MOESI Protocol,在MESI的基础上增加了一个状态:
-
Owned: 表示该数据块被当前Cache拥有,且主存中的是过时的
-
当总线上发来Read Miss信号,也即其他处理器需要读取这个数据项时,当前Cache可以直接将数据项发送给请求的处理器,而不需要先写回主存。此时状态由Modified变为Owned。
-
这样,相比于之前两个协议,减少了写回内存的次数.只在自己Miss或者Bus传来Write Miss或者Invalidate时才写回内存。
-
-
MESIF Protocol,在MOESI的基础上增加了一个状态:
-
Forward: 表示当前Cache拥有数据项,但其他Cache也有这个数据项的副本。
-
当总线上发来Read Miss信号时,当前Cache可以直接将数据项发送给请求的处理器,而不需要先写回主存。此时状态由Modified变为Forward。
-
这样,相比于之前的协议,减少了总线上的通信开销。
-
Coherence Miss¶
-
True Sharing Miss:
-
当一个共享数据项首次被某个处理器写入时,会传递无效信号
-
当其他处理器尝试访问这个数据项时,会发生Cache Miss,需要发生对应块的传输.
-
处理器
A读取了变量X,处理器B修改了变量X,然后处理器A再次尝试读取变量X。由于处理器B修改了X,处理器A的缓存中X的副本已经失效,因此处理器A再次读取时会发生True Sharing Miss。
-
-
False Sharing Miss:
-
在一个数据块中,仅有一个有效位,所以这个数据块中任何一部分的数据被修改,都会导致这整个数据块被标记为无效
-
因此,此时访问这个数据块中的其他数据,尽管它们实际上是有效的,但因为整个数据块被无效了,所以会发生Miss,这就是False Sharing Miss。
-
假设一个缓存行大小为 64 字节。变量 x 存储在该缓存行的字节 0-3,变量 y 存储在该缓存行的字节 4-7。处理器
A只修改变量x,而处理器B只读取变量y。当处理器A修改x时,包含x和y的整个缓存行在处理器B的缓存中会失效。当处理器B尝试读取y时,就会发生False Sharing Miss,即使y本身并没有被处理器A修改。
-
Distributed Shared Memory¶
在监听协议中,存在一个问题.对于invalidate信号,并不是所有处理器都需要接受,但是实际操作中只能广播,这就导致了通信开销过大。
那么,我们能不能实现定点打击,即只向需要的处理器发送invalidate信号呢?
为此,我们需要一个中心目录来跟踪每个数据块的状态和所在的Cache,这就是Directory-Based Protocols。
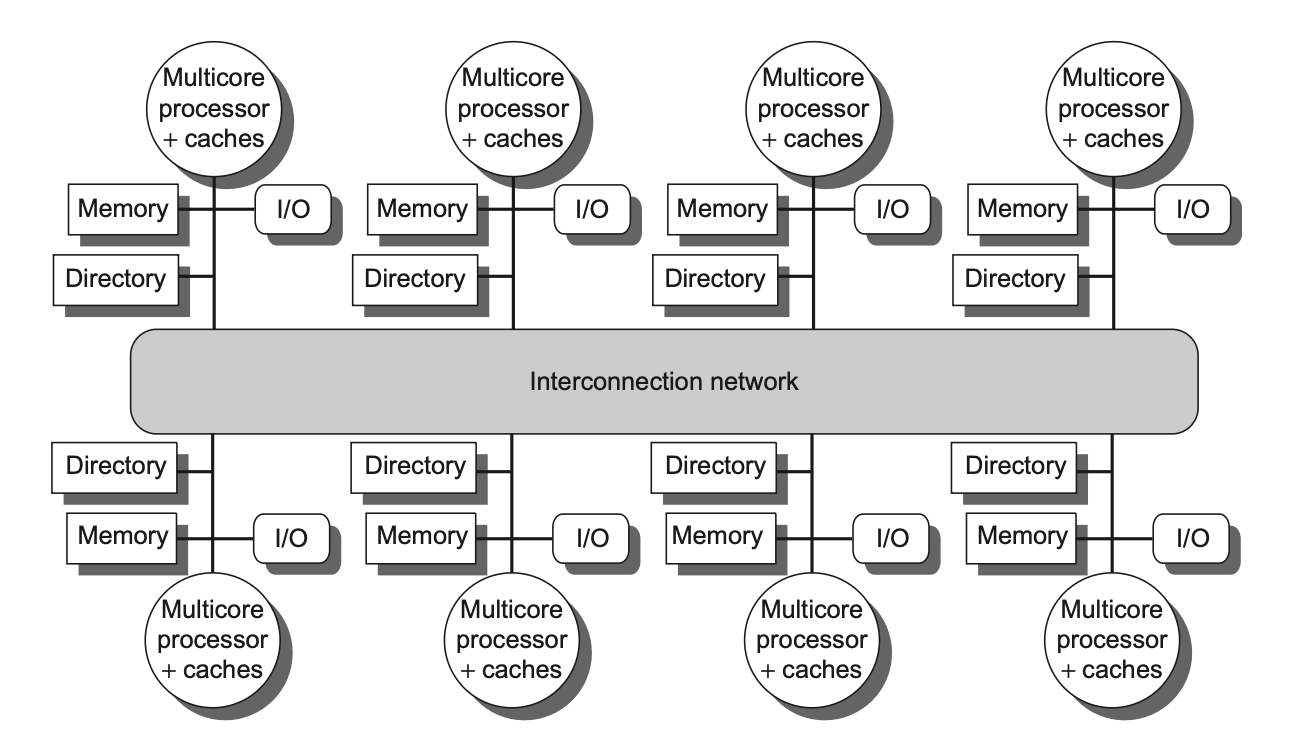
目录协议示意图
实际上,每个CPU的目录可能是逻辑上连续的,但物理上并不连续,因此需要一个映射表来将逻辑地址映射到物理地址。
Directory-Based Protocols¶
在目录协议中,数据块有如下的状态:
-
目录中的数据块(也就是目录项)状态:
-
Modified: 只有一个node(处理器)拥有这个数据块的副本,且这个副本是脏的。
-
Shared: 多个node拥有这个数据块的副本,且这些副本都是干净的。
-
Uncached: 没有任何node拥有这个数据块的副本。
-
-
在每个node的Cache中,数据块状态和监听协议的一样.
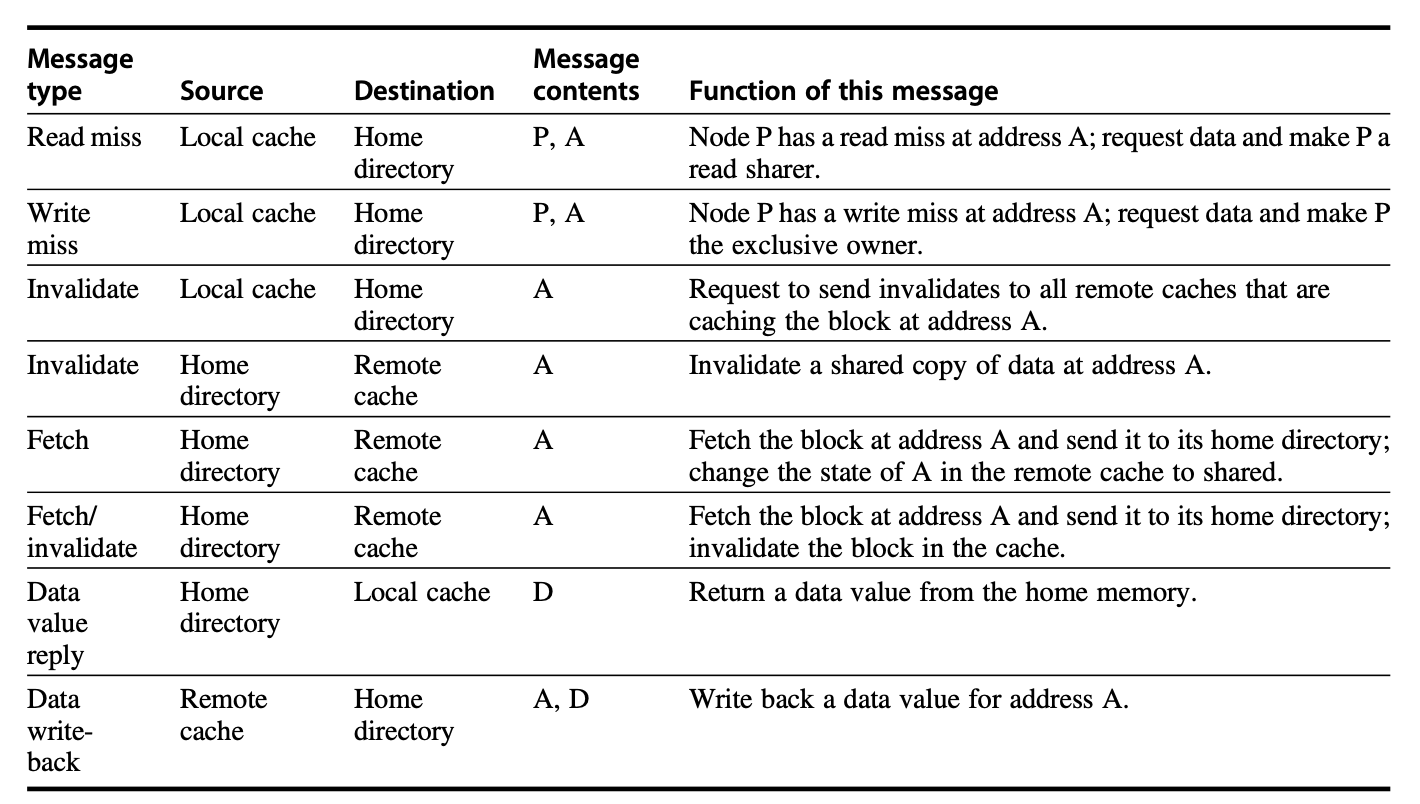
目录协议的操作
P : 发出请求的处理器编号
A : 数据块的地址
D : 数据内容
在目录中,每个目录项对应一个数据项,并存储:
-
数据块的状态(M/S/Uncached)
-
拥有这个数据块的node的列表(通常是一个位向量,向量的长度等于node的数量,对应位为1表示拥有,0表示没有)
下图即目录协议中,Cache数据项状态机,灰色代表其他Cache的信号,黑色代表当前Cache信号
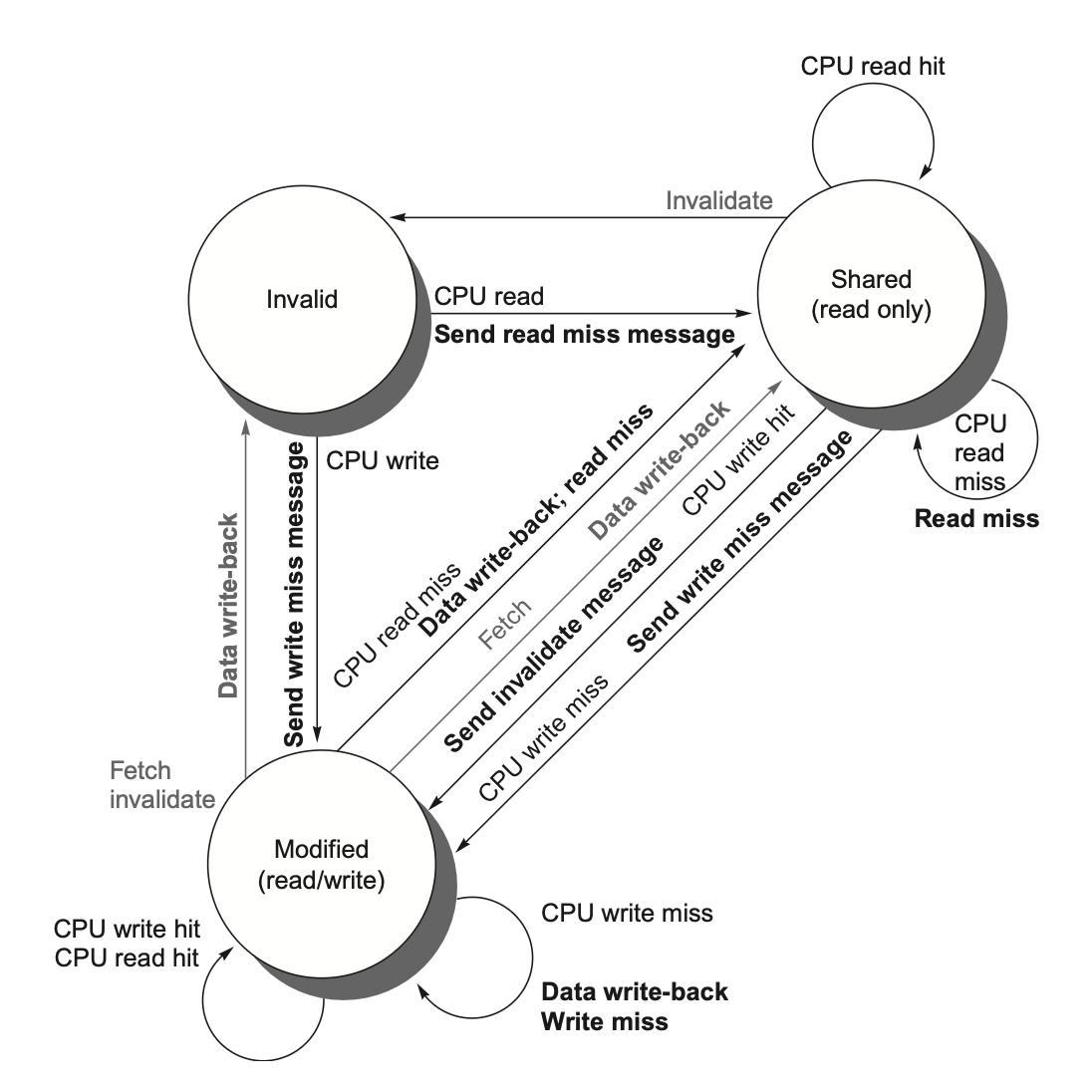
目录协议的Cache数据项状态机
目录中的目录项状态指示了当前数据块所有副本的情况,状态机如下:
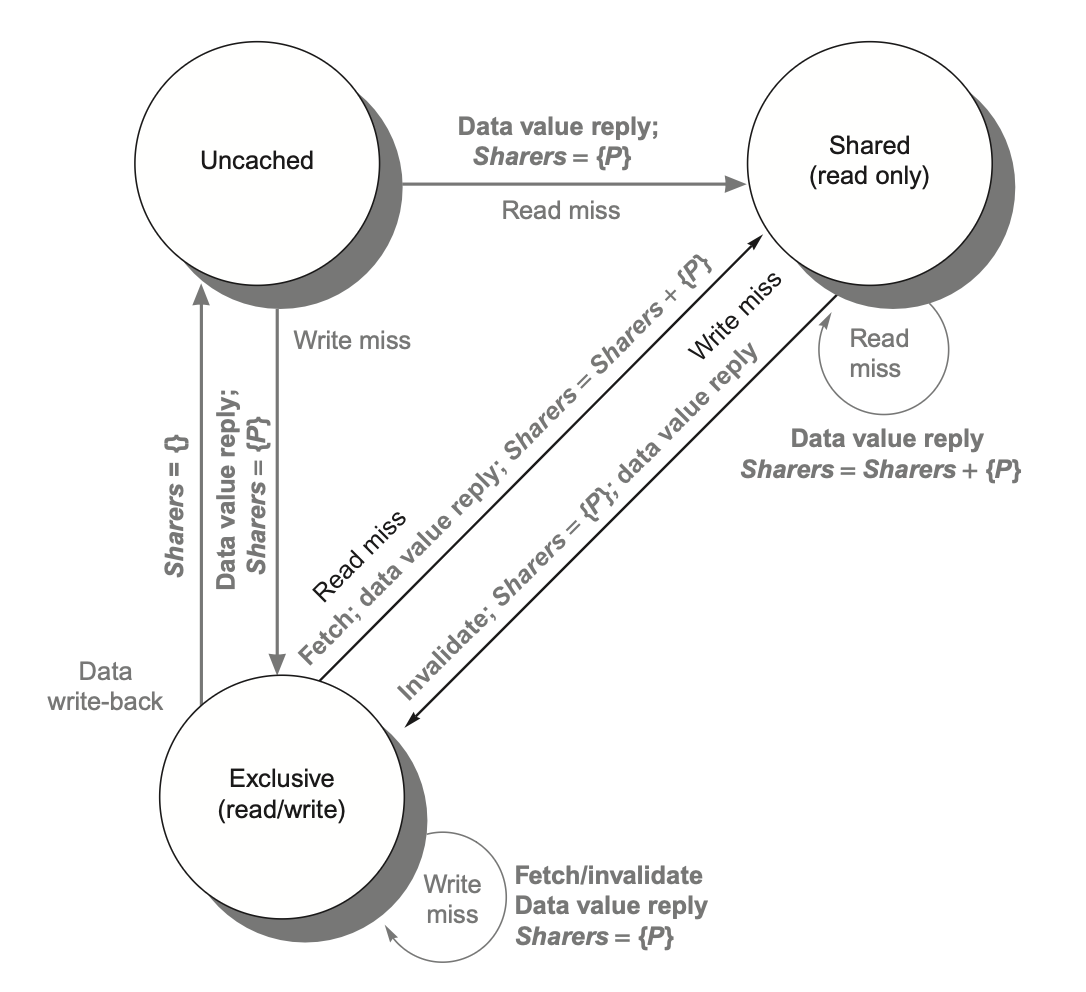
目录协议的目录项状态机
Cache需要与目录交互的情况就是发生了Miss,此时需要向目录发送请求,目录根据当前状态来决定如何处理请求。下面解释上面的状态机
-
数据项是Uncashed状态,即没有任何node拥有这个数据块的副本,此时:
-
读取必然发生Read Miss,目录会将数据块从主存中加载到当前node的Cache中,并将目录项状态设置为Shared,共享者列表初始化为该node
-
写操作也会导致Write Miss,目录会将数据块从主存中加载到当前node的Cache中,并将目录项状态设置为Modified,共享者列表初始化为该node
-
-
数据项是Shared状态,即多个node拥有这个数据块的副本,此时:
-
若发生Read Miss,可以从内存中把数据块加载到当前node的Cache中,共享者列表添加当前node
-
若发生Write Miss,目录会向请求节点发送值,并对该目录项中位向量为1(也即共享者列表成员)对应的node的cache发送Invalidate信号,然后将目录项状态设置为Modified,共享者列表初始化为请求写的node
-
-
数据项是Modified状态,即只有一个node拥有这个数据块的副本,此时:
-
发生Read Miss:
-
向所有者发送信号,所有者将该数据项发送给目录,状态变为Shared
-
目录将数据项写回内存并发送给请求的node,并将目录项状态设置为Shared,共享者列表添加当前node
-
注意,此时原本持有该数据项的node仍然在共享者列表中,因为它仍然拥有该数据块的副本
-
-
写回操作:所有的node自己发生miss,需要替换掉这个块:
- 写回内存,清空共享者列表,标记为Uncached
-
发生Write Miss:
-
向所有者发送信号,所有者将该数据项发送给目录,状态变为Invalid
-
目录将数据项写回内存并发送给请求的node,目录项为Modified不变,共享者列表清空并添加请求的node
-
-