Advanced SQL¶
约 3585 个字 488 行代码 1 张图片 预计阅读时间 24 分钟
在应用程序中,我们并不通常使用SQL语句来查询数据.这是因为,不是所有的查询语句都能使用SQL来表达,SQL也无法实现诸如用户交互等功能.因此,我们希望从一个编程语言(Programming Language)中调用SQL语句,并将结果返回给应用程序.
上述目标的实现可以通过如下两种方法:
-
API:使用编程语言提供的数据库连接库或框架,通过函数调用来执行SQL语句和处理结果
-
Embedded SQL:将SQL语句直接嵌入到宿主编程语言的代码中,在预编译阶段由专门的预处理器处理。
JDBC and ODBC¶
JDBC(Java Database Connectivity)和ODBC(Open Database Connectivity)是两种常用的数据库连接API。它们提供了一组标准的接口和类库,使得应用程序可以通过统一的方式访问不同类型的数据库。
JDBC使用Java,ODBC使用C,C++,C#等语言.
它们主要的功能是:
-
连接到数据库服务器
-
向数据库服务器发送SQL命令
-
抓取结果元组到变量中.
SQLJ是Java中的Embedded SQL.
JDBC¶
引入java.sql.*使得我们可以使用JDBC API来连接数据库,执行SQL语句和处理结果集.
Example
public static void JDBCexample(String dbid, String userid, String passwd) {
try {
// 1. 建立数据库连接
Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@db.yale.edu:2000:univdb", userid, passwd);
// 2. 创建语句对象
Statement stmt = conn.createStatement();
// 3. 执行SQL语句并处理结果(此处省略)
// ... Do Actual Work ...
// 4. 关闭资源
stmt.close();
conn.close();
}
catch (SQLException sqle) {
// 5. 异常处理
System.out.println("SQLException : " + sqle);
}
}
下面,我们将介绍JDBC的几个重要概念和功能:
Connection¶
在执行SQL语句之前,我们必须先连接到数据库.在JDBC中,我们使用DriverManager类来获取一个数据库连接对象Connection.
import java.sql.*;
public class JDBCExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/testdb"; // 数据库 URL
String user = "root";
String password =
"123456";
try {
// 1. 加载 JDBC 驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 建立数据库连接
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println("连接成功!");
conn.close(); // 关闭连接
} catch (SQLException e) {
e.printStackTrace();
}
}
}
在使用JDBC连接数据库时,我们需要提供以下信息:
-
数据库 URL:指定数据库的类型、位置和端口号,例如
jdbc:mysql://localhost:3306/testdb。 -
用户名和密码:用于身份验证的凭据。
-
JDBC 驱动:用于与特定数据库进行通信的驱动程序,通常需要在项目中添加相应的依赖库。
Exception¶
看过Python代码的都知道,我们可以使用try...except语句来捕获异常,在Java中,我们使用try...catch语句来捕获异常.
在JDBC中,我们使用SQLException类来处理SQL相关的异常.它是一个检查异常(Checked Exception),这意味着我们必须显式地处理它.
try {
// 可能抛出 SQLException 的代码
} catch (SQLException e) {
// 处理异常
System.out.println("SQL 错误代码: " + e.getErrorCode());
System.out.println("SQL 状态码: " + e.getSQLState());
System.out.println("错误消息: " + e.getMessage());
}
在捕获异常时,我们可以使用SQLException类提供的方法来获取更多的错误信息:
- getErrorCode():获取数据库特定的错误代码。
-
getSQLState():获取 SQL 状态码,通常是一个 5 位的字符串。 -
getMessage():获取详细的错误消息。
Statement¶
在确立连接之后,我们就需要将SQL语句发送到数据库服务器,并让它执行这些语句.在JDBC中,我们使用Statement类来执行SQL语句.
Statement类提供了三种类型的语句对象:
-
Statement:用于执行简单的 SQL 语句,如查询、插入、更新和删除。
-
PreparedStatement:用于执行预编译的 SQL 语句,支持参数化查询,通常用于执行多次相同的 SQL 语句,在下面会单独介绍
-
CallableStatement:用于调用存储过程,支持输入和输出参数。
import java.sql.*;
public class JDBCExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/testdb"; // 数据库 URL
String user = "root";
String password = "123456";
try {
// 1. 加载 JDBC 驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 建立数据库连接
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println("连接成功!");
// 3. 创建 Statement 对象
Statement stmt = conn.createStatement();
// 4. 执行 SQL 查询
String sql = "SELECT id, username, email FROM users";
ResultSet rs = stmt.executeQuery(sql);
// 5. 关闭资源
rs.close();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
-
createStatement():创建一个Statement对象,用于执行 SQL 语句。 -
executeQuery(String sql):执行 SQL 查询,返回一个ResultSet对象。 -
同理也有
executeUpdate(String sql)用于执行更新操作,返回一个整数,表示受影响的行数. -
execute(String sql):执行 SQL 语句,返回一个布尔值,指示是否有结果集。
Get ResultSet¶
ResultSet对象用于存储查询结果集,它是一个指向结果集的游标(cursor),我们可以使用它来遍历结果集中的每一行数据.
import java.sql.*;
public class JDBCExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/testdb"; // 数据库 URL
String user = "root";
String password = "123456";
try {
// 1. 加载 JDBC 驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 建立数据库连接
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println("连接成功!");
// 3. 创建 Statement 对象
Statement stmt = conn.createStatement();
// 4. 执行 SQL 查询
String sql = "SELECT id, username, email FROM users";
ResultSet rs = stmt.executeQuery(sql);
// 5. 处理查询结果
while (rs.next()) {
int id = rs.getInt("id");
String username = rs.getString("username");
String email = rs.getString("email");
System.out.println("ID: " + id + ", 用户名: " + username + ", 邮箱: " + email);
}
// 6. 关闭资源
rs.close();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
-
next():将游标移动到下一行,返回true如果有更多行,否则返回false。 -
getInt(String columnLabel):获取指定列的整数值。 -
getString(String columnLabel):获取指定列的字符串值。 -
getFloat(String columnLabel):获取指定列的浮点值。 -
上面的函数不仅接受列名,也可以接受列的索引,例如
getInt(1)表示获取第一列的值.
Prepared Statement¶
预处理语句(Prepared Statement)是一种特殊的SQL语句,它允许数据库驱动程序在执行前对SQL语句进行预编译,从而提高执行效率并增强安全性。
主要特点:
-
防止 SQL 注入:通过占位符
?绑定参数,避免恶意 SQL 代码执行。 -
提高查询性能:SQL 语句会被 预编译 并缓存,减少 SQL 解析和优化的开销。
-
代码结构更清晰:与普通
Statement相比,可读性更好,减少手动拼接 SQL 的错误。
使用 PreparedStatement 的基本步骤如下:
-
加载 JDBC 驱动
-
建立数据库连接
-
创建
PreparedStatement对象 -
设置 SQL 参数
-
执行 SQL
-
处理查询结果
-
关闭资源
代码示例
import java.sql.*;
public class JDBCExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/testdb"; // 数据库 URL
String user = "root";
String password = "123456";
String sql = "INSERT INTO users (username, password, email) VALUES (?, ?, ?)";
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
// 设置参数
pstmt.setString(1, "Alice");
pstmt.setString(2, "securePass");
pstmt.setString(3, "alice@example.com");
// 执行 SQL
int rowsInserted = pstmt.executeUpdate();
System.out.println("插入 " + rowsInserted + " 行数据");
} catch (SQLException e) {
e.printStackTrace();
}
}
}
String sql = "SELECT id, username, email FROM users WHERE username = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, "Alice"); // 绑定查询参数
ResultSet rs = pstmt.executeQuery(); // 执行查询
while (rs.next()) {
int id = rs.getInt("id");
String username = rs.getString("username");
String email = rs.getString("email");
System.out.println("ID: " + id + ", 用户名: " + username + ", 邮箱: " + email);
}
} catch (SQLException e) {
e.printStackTrace();
}
-
对于用
?表示的参数,我们使用setXXX方法来设置它们的值,其中XXX表示参数的类型,例如setString,setInt,setFloat等. -
setXXX方法的第一个参数是参数的索引,从1开始,第二个参数是要设置的值.
SQL Injection¶
如果不使用预处理语句,编译器不会把用户的输入仅当成字符串,那么就有可能把用户输入的数据当作执行语句之类的,从而实现控制之外的效果.
Example
对于以下查询语句
如果用户输入"X' or Y=`Y"
那么查询语句就会变成
也就是
这样就会查询所有结果
亦或者用户输入"X’; update instructor set salary = salary + 10000; "
那查询语句就变成了
这样甚至会多执行一条指令.因此,使用预编译语句是很有必要的,它将特殊字符转义,从而避免了SQL注入攻击.
Metadata¶
JDBC提供了两个主要的元数据接口:
-
DatabaseMetaData:提供关于整个数据库的信息
-
ResultSetMetaData:提供关于查询结果集的信息
// 获取数据库元数据
Connection conn = DriverManager.getConnection(url, username, password);
DatabaseMetaData dbMetaData = conn.getMetaData();
// 获取数据库基本信息
System.out.println("数据库产品名称: " + dbMetaData.getDatabaseProductName());
System.out.println("数据库版本: " + dbMetaData.getDatabaseProductVersion());
System.out.println("驱动名称: " + dbMetaData.getDriverName());
System.out.println("驱动版本: " + dbMetaData.getDriverVersion());
// 获取表信息
ResultSet tables = dbMetaData.getTables(null, null, "%", new String[]{"TABLE"});
while (tables.next()) {
System.out.println("表名: " + tables.getString("TABLE_NAME"));
}
// 获取查询结果集的元数据
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM instructor");
ResultSetMetaData rsMetaData = rs.getMetaData();
// 输出结果集列信息
int columnCount = rsMetaData.getColumnCount();//获取列数
for (int i = 1; i <= columnCount; i++) {
System.out.println("列名: " + rsMetaData.getColumnName(i));
System.out.println("列类型: " + rsMetaData.getColumnTypeName(i));
}
Transaction Control in JDBC¶
默认情况下,每句SQL语句被当作独立隔离的一个事务.
关闭自动提交:
conn.setAutoCommit(false);
手动提交:
conn.commit();
手动回滚
conn.rollback
SQLJ¶
SQLJ 是 Java 中的嵌入式 SQL 技术,它允许开发者在 Java 程序中直接嵌入标准 SQL 语句。
主要特点:
-
静态 SQL:SQL 语句在编译时就被检查语法错误,而不是在运行时
-
更简洁的代码:相比 JDBC,代码量更少、更易读
-
更好的性能:由于预编译,执行效率通常高于动态 SQL
-
类型安全:在编译时进行类型检查,减少运行时错误
语法示例:
SQLJ 语句以 '#sql' 开头,并使用花括号 '{}' 包围 SQL 语句:
// SQLJ 导入
import sqlj.runtime.*;
import sqlj.runtime.ref.*;
public class SQLJExample {
public static void main(String[] args) {
try {
// 注册 JDBC 驱动并连接数据库
Class.forName("oracle.jdbc.driver.OracleDriver");
DefaultContext.setDefaultContext(
Oracle.getConnection("jdbc:oracle:thin:@localhost:1521:orcl",
"scott", "tiger"));
// 声明上下文和迭代器
#sql iterator DeptIter (String deptName, float avgSalary);
// 执行查询
DeptIter deptIter;
#sql deptIter = {
SELECT dept_name, AVG(salary)
FROM instructor
GROUP BY dept_name
};
// 处理结果
while (deptIter.next()) {
System.out.println(deptIter.deptName() + ": " +
deptIter.avgSalary());
}
// 关闭迭代器
deptIter.close();
} catch (Exception e) {
System.err.println("Error: " + e);
}
}
}
ODBC¶
ODBC 采用 四层架构,如下:
| 组件 | 作用 |
|---|---|
| 应用程序 | 调用 ODBC API 进行数据库操作 |
| ODBC 驱动管理器 | 管理 ODBC 驱动,解析 SQL 语句并传递给合适的数据库驱动 |
| ODBC 驱动 | 由数据库厂商提供,负责将 ODBC 请求转换为数据库特定的调用 |
| 数据库 | 实际存储数据,执行 SQL 查询 |
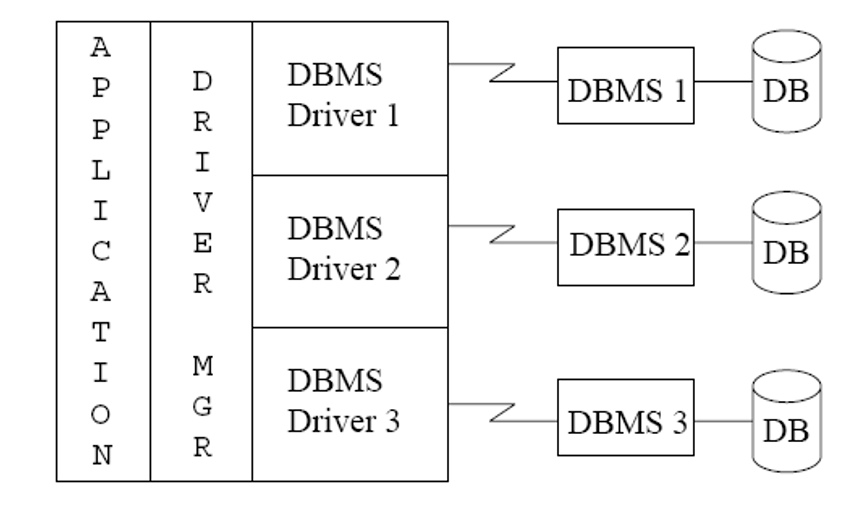
示例代码:
#include <windows.h>
#include <sql.h>
#include <sqlext.h>
#include <stdio.h>
void printError(SQLHANDLE handle, SQLSMALLINT type) {
SQLCHAR sqlstate[6], message[SQL_MAX_MESSAGE_LENGTH];
SQLINTEGER native_error;
SQLSMALLINT i = 1, length;
while (SQLGetDiagRec(type, handle, i++, sqlstate, &native_error, message,
sizeof(message), &length) == SQL_SUCCESS) {
printf("SQLSTATE: %s\n", sqlstate);
printf("消息: %s\n", message);
}
}
int main() {
SQLHENV henv;
SQLHDBC hdbc;
SQLHSTMT hstmt;
SQLRETURN ret;
// 定义结果列的变量
SQLCHAR dept_name[50];
SQLFLOAT avg_salary;
SQLLEN dept_name_len, avg_salary_len;
// 分配环境句柄并设置
SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &henv);
SQLSetEnvAttr(henv, SQL_ATTR_ODBC_VERSION, (SQLPOINTER)SQL_OV_ODBC3, 0);
// 分配连接句柄并连接
SQLAllocHandle(SQL_HANDLE_DBC, henv, &hdbc);
ret = SQLConnect(hdbc,
(SQLCHAR*)"MySQLDSN", SQL_NTS,
(SQLCHAR*)"root", SQL_NTS,
(SQLCHAR*)"password", SQL_NTS);
if (SQL_SUCCEEDED(ret)) {
printf("数据库连接成功!\n");
// 分配语句句柄
SQLAllocHandle(SQL_HANDLE_STMT, hdbc, &hstmt);
// 准备SQL语句
const char *sql = "SELECT dept_name, AVG(salary) AS avg_salary FROM instructor GROUP BY dept_name";
// 执行SQL语句
ret = SQLExecDirect(hstmt, (SQLCHAR*)sql, SQL_NTS);
if (SQL_SUCCEEDED(ret)) {
// 绑定结果列
SQLBindCol(hstmt, 1, SQL_C_CHAR, dept_name, sizeof(dept_name), &dept_name_len);
SQLBindCol(hstmt, 2, SQL_C_DOUBLE, &avg_salary, 0, &avg_salary_len);
// 获取数据
while ((ret = SQLFetch(hstmt)) == SQL_SUCCESS) {
printf("系名: %s, 平均工资: %.2f\n", dept_name, avg_salary);
}
if (ret != SQL_NO_DATA) {
printError(hstmt, SQL_HANDLE_STMT);
}
} else {
printf("执行查询失败!\n");
printError(hstmt, SQL_HANDLE_STMT);
}
// 释放语句句柄
SQLFreeHandle(SQL_HANDLE_STMT, hstmt);
// 断开连接
SQLDisconnect(hdbc);
} else {
printf("数据库连接失败!\n");
printError(hdbc, SQL_HANDLE_DBC);
}
// 释放连接和环境句柄
SQLFreeHandle(SQL_HANDLE_DBC, hdbc);
SQLFreeHandle(SQL_HANDLE_ENV, henv);
return 0;
}
Embedded SQL¶
在除了Java之外的语言嵌入SQL语句,我们一般使用EXEC SQL <embedded SQL statement>.其中宿主语言被称为host language,而嵌入的SQL语句被称为embedded SQL statement.在C语言中,我们使用EXEC-SQL来表示嵌入的SQL语句.
-
连接服务器
-
使用
EXEC-SQL connect to server user user-name using password;连接服务器 -
这里
server,username,password分别是服务器,用户名与对应的密码
-
-
使用变量
-
嵌入SQL允许使用原语言中的变量
-
在使用时需要在前面加上
:,例如:credit_amount -
在使用这种变量时,必须以如下方法提前声明:
其中int credit-amount ;这种语句怎么写由原语言决定
-
-
Embedded SQL Query
-
为了使用这样的语句,我们写
declare c cursor for <SQL query> -
这样,
c就存储了查询的结果表 -
例如:
-
在定义完之后,我们使用如下语句执行查询:
EXEC SQL open c ; -
然后,我们可以把查询到的数据存到变量中:
EXEC SQL fetch c into :si, :sn;这样存储了查询结果的一个元组.如果想得到全部内容,需要连续的调用. -
最后,关闭:
EXEC SQL close c;
-
-
Embedded SQL for update,insert and delete
-
在声明时加上
for update: -
遍历来更新
EXEC SQL open c; /* 声明变量用于存储结果 */ EXEC SQL BEGIN DECLARE SECTION; char name[20]; char dept[20]; float salary; EXEC SQL END DECLARE SECTION; /* 循环获取每条记录 */ while (1) { EXEC SQL fetch c into :name, :dept, :salary; /* 检查是否已到结尾 */ if (sqlca.sqlstate == 02000) { break; } /* 在这里处理每条记录 */ if (salary < 40000) { /* 对获取的记录执行更新操作 */ EXEC SQL update instructor set salary = salary * 1.05 where current of c; } } EXEC SQL close c;
-
Procedural Constructs in SQL¶
SQL Functions¶
SQL中可以创建函数并调用,示例如下:
create function dept_count (dept_name varchar(20))
returns integer
begin
declare d_count integer;
select count (* ) into d_count
from instructor
where instructor.dept_name = dept_name
return d_count;
end
select dept_name, budget
from department
where dept_count (dept_name ) > 12
上面的语句找到拥有超过12名导师的院系的名字和预算
Table Functions¶
返回结果是一个表
create function instructors_of (dept_name char(20) )
returns table (ID varchar(5),
name varchar(20),
dept_name varchar(20),
salary numeric(8,2))
return table
(select ID, name, dept_name, salary
from instructor
where instructor.dept_name = instructors_of.dept_name)
select * from table (instructors_of (‘Music’))
SQL Procedures¶
自定义一个程序,然后使用call关键字调用
CREATE PROCEDURE calculate_department_stats
(IN dept_name VARCHAR(20),
OUT avg_salary DECIMAL(10,2),
OUT instructor_count INTEGER)
BEGIN
-- 计算平均工资
SELECT AVG(salary) INTO avg_salary
FROM instructor
WHERE instructor.dept_name = dept_name;
-- 计算教师数量
SELECT COUNT(*) INTO instructor_count
FROM instructor
WHERE instructor.dept_name = dept_name;
END;
-- 声明变量接收输出参数
DECLARE @avg_salary DECIMAL(10,2);
DECLARE @count INTEGER;
-- 调用存储过程
CALL calculate_department_stats('Computer Science', @avg_salary, @count);
-- 使用输出结果
SELECT @avg_salary AS average_salary, @count AS instructor_count;
IN表示输入参数,OUT表示输出参数
Procedural Constructs¶
-
SQL中有支持其他编程语言的控制结构,例如
if-then,while,repeat等 -
这些结构被称为
control structures,它们允许我们在SQL中编写更复杂的逻辑 -
Compound statement是一个包含多个SQL语句的块,可以在控制结构中使用-
BEGIN和END用于包裹一个复合语句块,在这个块中可以包含多个SQL语句 -
在复合语句中可以定义局部变量,使用
DECLARE语句
-
复合语句有如下常见的例子
-
循环
declare n integer default 0; while n < 10 do set n = n + 1 end while repeat set n = n – 1 until n = 0 end repeat在SQL中,也有for循环,其作用是迭代结果中的每一个元组
-
选择
if-then语句同样也存在
其一般格式为:
if boolean expression then statement or compound statement elseif boolean expression then statement or compound statement else statement or compound statement end ifcase
SQL中也有
case语句,其示例在第三章出现
External Procedures¶
在SQL中,我们可以使用外部过程,也就是在SQL中调用其他语言编写的函数,例如C,Java等
-
这些外部过程可以在SQL中被调用,并且可以访问数据库中的数据
-
例如,我们可以使用C语言编写一个函数,然后在SQL中调用它
CREATE FUNCTION calculate_bonus (emp_id INT)
RETURNS DECIMAL(10,2)
LANGUAGE C
EXTERNAL NAME 'com.example.CalculateBonus.calculateBonus'
在上面的例子中,我们创建了一个名为calculate_bonus的函数,它调用了C语言编写的calculateBonus函数
值得关注的是,在使用外部过程时,有可能会引发安全问题,例如用户通过外部函数访问到了本来无权访问的数据。
为保证安全,一般有两种做法:
-
使用沙箱环境(SandBox):将外部过程限制在一个受控的环境中,防止其访问敏感数据。这一般用于java等安全的语言
-
隔离进程:将外部过程运行在一个独立的进程中,限制其对数据库的访问权限。这一般用于C等不安全的语言
Triggers¶
顾名思义,触发器是在发生特定时间时自动执行的的 SQL 语句。触发器通常用于实现数据完整性、审计、自动化等功能。
Trigger的ECA模型:
-
Event:触发器的触发事件,例如插入、更新或删除操作
-
Condition:触发器的条件,只有在满足特定条件时才会执行触发器的操作
-
Action:触发器在满足条件时执行的操作,例如插入、更新或删除数据
触发器按执行时间分为:
-
BEFORE 触发器:在数据库操作之前触发
-
AFTER 触发器:在数据库操作之后触发
-
INSTEAD OF 触发器:替代原始操作的触发器(主要用于视图)
按触发事件分为:
-
INSERT 触发器:在插入数据时触发
-
UPDATE 触发器:在更新数据时触发
-
DELETE 触发器:在删除数据时触发
例子
CREATE TRIGGER before_insert_instructor
BEFORE INSERT ON instructor
FOR EACH ROW
BEGIN
-- 检查新插入的工资是否大于 100000
IF NEW.salary > 100000 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Salary cannot exceed 100000';
END IF;
END;
-
NEW关键字表示新插入的行 -
OLD关键字表示被删除或更新的行 -
SIGNAL语句用于抛出自定义异常 -
FOR EACH ROW表示触发器在每一行操作时都执行
CREATE TRIGGER account_trigger
AFTER UPDATE OF balance ON account
REFERENCING NEW ROW AS nrow
OLD ROW AS orow
FOR EACH ROW
WHEN (nrow.balance - orow.balance >= 200000 OR
orow.balance - nrow.balance >= 50000)
BEGIN
INSERT INTO account_log
VALUES (nrow.account_number,
nrow.balance - orow.balance,
CURRENT_TIMESTAMP);
END;
-
AFTER UPDATE OF balance表示在balance列更新后触发 -
On account表示触发器作用于account表 -
REFERENCING NEW ROW AS nrow OLD ROW AS orow用于引用新旧行的值 -
WHEN子句用于指定触发器的条件
Statement Level Triggers¶
在使用for each row时,触发器会一行一行地将action应用,如果我们想直接对表进行操作,可以使用for each statement
CREATE TRIGGER order_update_trigger
AFTER UPDATE ON orders
FOR EACH STATEMENT
BEGIN
INSERT INTO system_logs (log_message)
VALUES ('Orders table updated');
END;
-
在这样的情况下,触发器在一个语句执行后触发,而不关心这个语句影响了多少行.
-
不然,如果一个语句影响了100行,那么使用
for each row的触发器就会执行100次 -
在这样的情况下,
OLD和NEW关键字就不再适用,转而代之的是new table和old table,它们分别表示新的表和旧的表
When Not To Use Triggers¶
在早期,触发器曾被广泛使用于多种场景,但随着数据库技术的发展,很多场景有了更好的替代方案:
-
维护汇总数据
-
早期做法:使用触发器在原始数据变化时自动更新汇总表(如各院系总工资)
-
现代替代:现代数据库提供内置的物化视图(Materialized Views)功能,能自动维护汇总数据,性能更好且维护成本更低
-
-
数据库复制
-
早期做法:触发器记录变更到特殊的变更表(delta relations),然后由单独进程将这些变更应用到副本
-
现代替代:数据库系统提供内置的复制支持,如主从复制、日志传输等,更可靠且性能更好
-
-
业务逻辑封装
-
早期做法:在触发器中实现复杂的业务规则
-
现代替代:使用封装设施(存储过程、ORM层的业务逻辑)来实现业务规则
-
定义专门的更新方法而不是依赖触发器
-
将操作作为更新方法的一部分执行,而非通过触发器
- 数据验证
-
-
早期做法:使用触发器验证数据完整性
-
现代替代:使用约束(CHECK、FOREIGN KEY等)或应用层验证
-
-
跨数据库操作
-
早期做法:触发器执行跨数据库更新
-
现代替代:使用事务管理器、消息队列或微服务架构
-
Cascade Trigger
设置不当的触发器很可能导致级联触发器(Cascade Trigger)的问题,即一个触发器的执行会导致另一个触发器被触发,从而形成循环调用,最终可能导致性能下降或死锁等问题。