基本块和轨迹¶
约 2073 个字 40 行代码 4 张图片 预计阅读时间 11 分钟
这一章主要讲怎么对IR进行优化
总的来说,IR 指令与真实机器指令之间的差距,主要源于以下三种 IR 结构:
-
CJUMP — IR 中的条件跳转
CJUMP(cond, l_true, l_false)有两个目标标签,条件为真跳转到一个标签,条件为假跳转到另一个。但真实机器的条件跳转指令在条件为假时是直通(fall-through)到下一条指令的,而不是跳转到两个不同的标签。 -
ESEQ —
ESEQ(s, e)表示先执行语句s,再返回表达式e的值。但是我们希望能以任意顺序执行语句和表达式,而不受 ESEQ 的限制。 -
CALL — 首先,
call的参数列表出现了和ESEQ一样的限制,参数必须按从左到右的顺序求值.其次,函数的嵌套调用可能会带来寄存器相关的问题,比如CALL(f, [CALL(g, args)])可能会导致g的调用覆盖掉f的返回值寄存器.
那么,如何解决呢?
Example
对于如下这个IR Tree
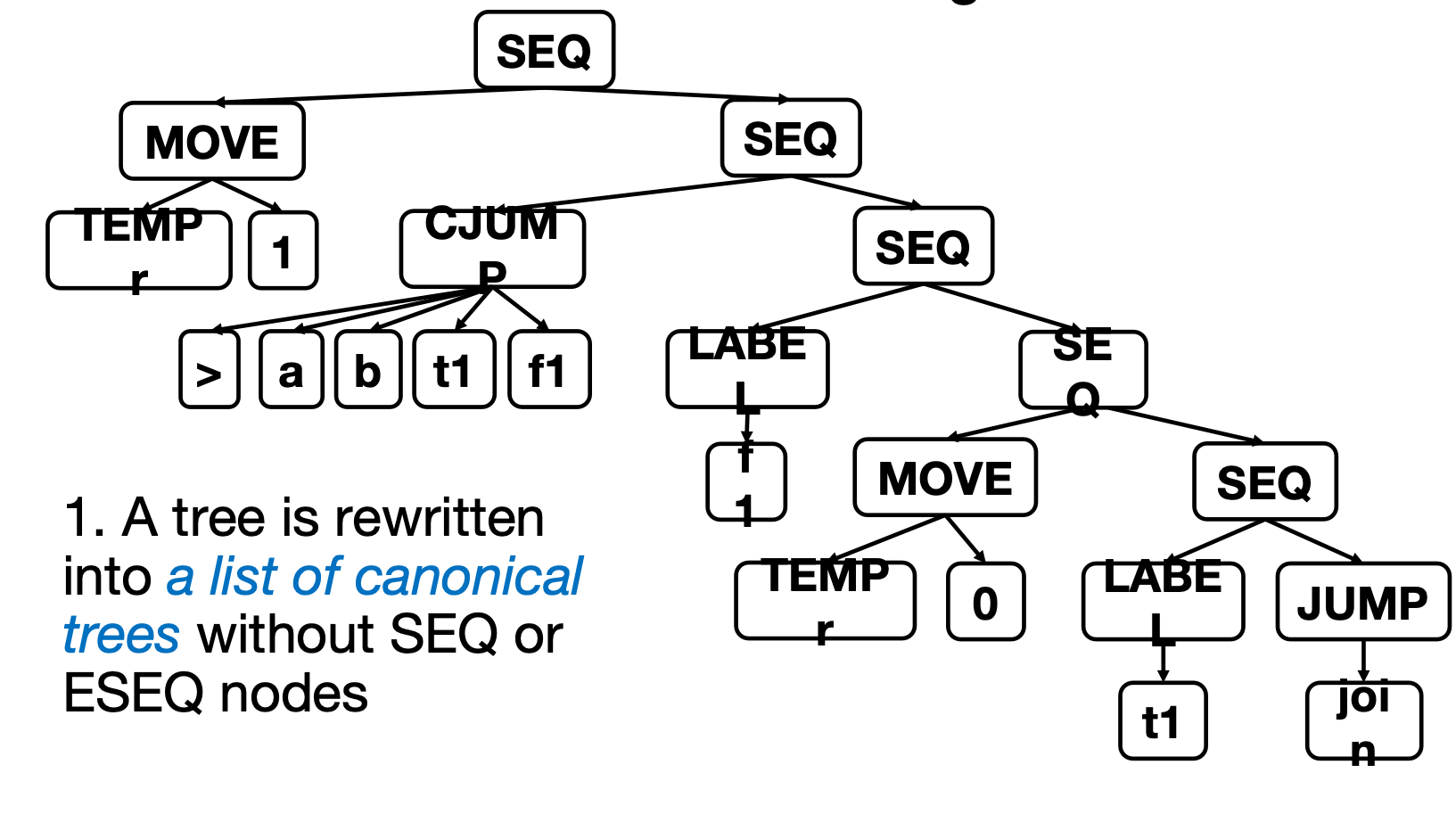
显然,它对应的C语言是:
首先,我们把它拆分成一堆规范(canonical)树:
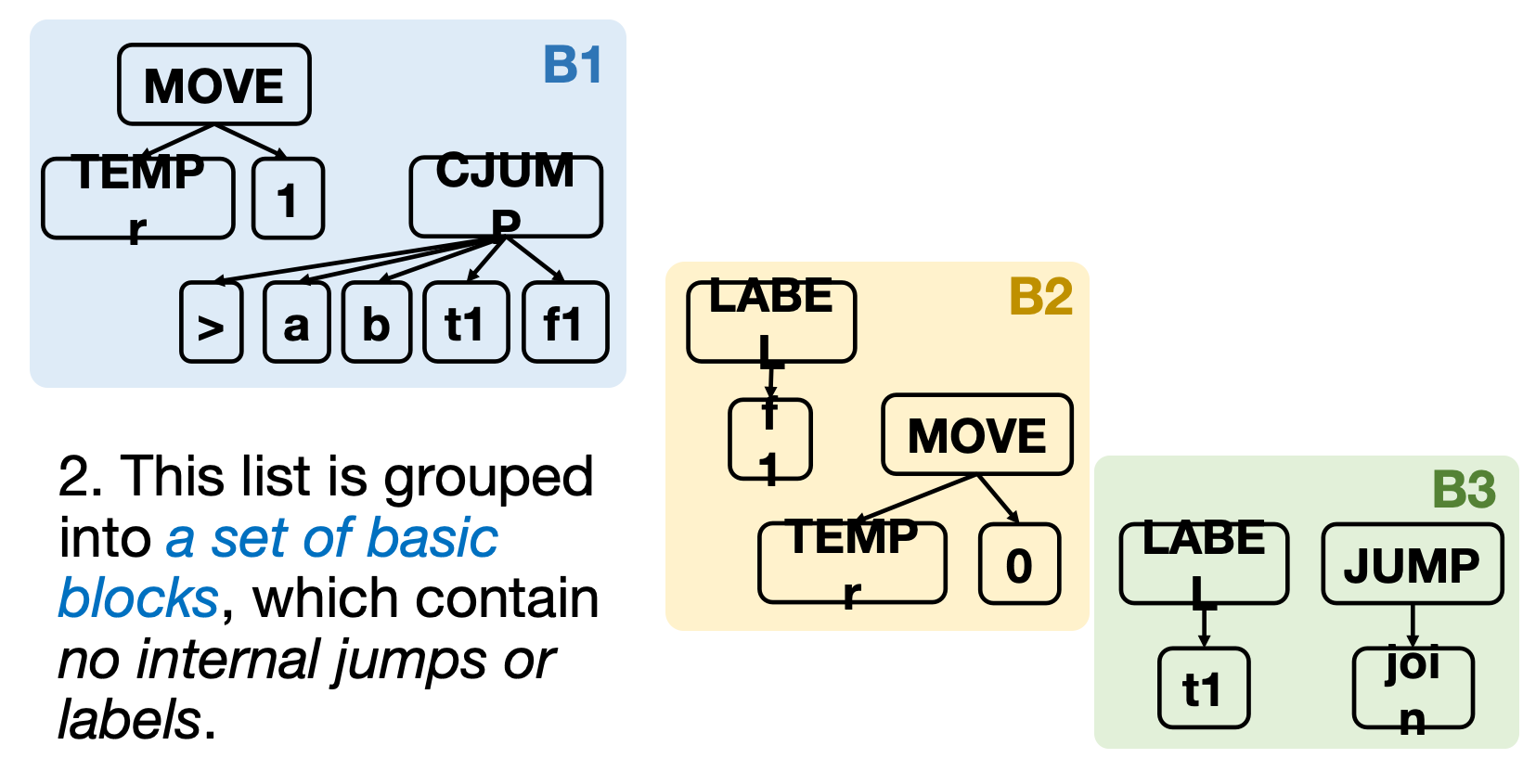
这一步消去了ESEQ(if any)与SEQ指令,并且划分了B1``B2``B3三个基本块.
基本块(Basic Block)
-
基本块是指一段连续的指令序列,满足以下条件:
-
只有第一个指令可以被跳转到(即有一个标签)
-
只有最后一个指令可以跳转到其他地方(即是一个跳转指令)
-
-
基本块内部不能相互跳转
然后,我们把这些基本块连接成一个个轨迹(trace):
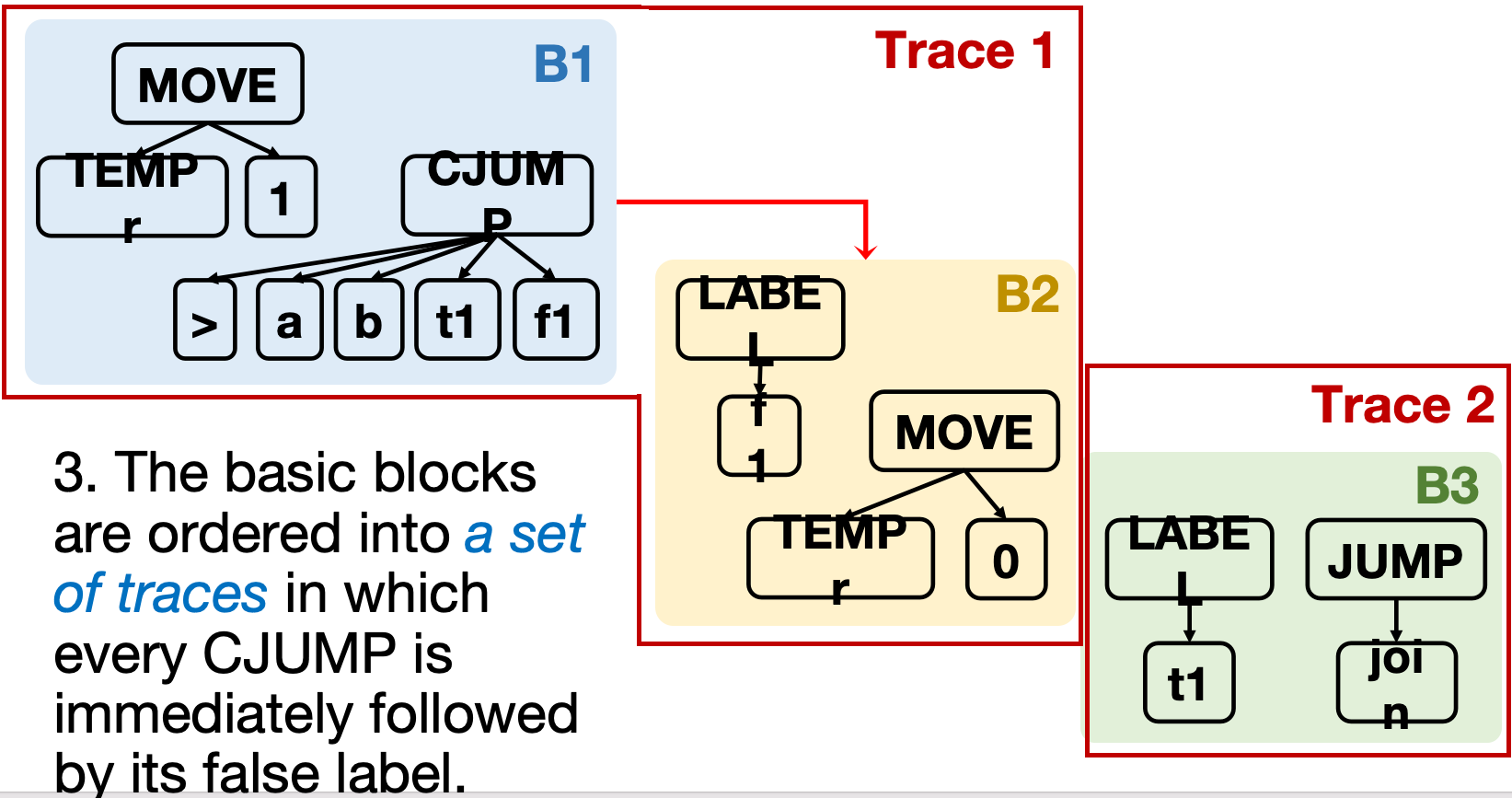
这里,我们之所以要把B1和B2连接成一个轨迹,是因为如果B1的CJUMP的条件为假,它会跳转到B2,而不是B3,因此我们把它们连接成一个轨迹,这样就可以消去CJUMP指令的假分支,从而得到更接近真实机器指令的IR Tree.
Canonical Trees¶
规范树 (Canonical Trees)
满足以下性质:
-
No
SEQorESEQ:规范树中不包含SEQ和ESEQ节点。 -
CALL的父节点限制:每个CALL节点的父节点只能是EXP(…)或MOVE(TEMP t, …)。
在拥有了以上基础性质后,规范树有以下良好性质
每棵规范树只包含一个语句节点,即根节点。其余节点全部是表达式节点。这是因为 SEQ 和 ESEQ 已经被消除(表达式节点的父节点只能是这两个),且 CALL 的父节点限制确保了 CALL 不会出现在表达式中。
CALL 节点的父节点必须是规范树的根节点,并且只能是 EXP(..) 或 MOVE(TEMP t, ..)。
因此,一棵规范树中最多只有一个 CALL 节点,因为 EXP(…) 和 MOVE(TEMP t, ...) 各自只能包含一个 CALL。
为了得到一个规范树,我们采取如下做法:
消除 ESEQ:¶
通过将
ESEQ中的语句提升到外层来消除ESEQ。
例如嵌套的 ESEQ 可以通过如下方式展开:
即:把内层 ESEQ 的语句 \(s_2\) 和外层 ESEQ 的语句 \(s_1\) 合并为一个 SEQ(s1, s2),最终只保留一个 ESEQ,其语句部分按顺序执行 \(s_1\) 和 \(s_2\),表达式部分返回 \(e\)。不断重复此过程,即可逐步消去所有 ESEQ。
Commute 条件
在右子树场景中,\(s\) 与 \(e_1\) 可交换 (commute),当且仅当:
- \(s\) 所写入(赋值)的临时变量和内存位置不被 \(e_1\) 所引用;
- 且 \(s\) 和 \(e_1\) 不会同时执行外部 I/O 操作。
若 \(s\) 与 \(e_1\) commute,则可以将 \(s\) 直接提到外层,无需引入临时变量:
BINOP(op, e1, ESEQ(s, e2)) \(\;\to\;\) ESEQ(s, BINOP(op, e1, e2))
若 \(s\) 与 \(e_1\) 不 commute,则需要先将 \(e_1\) 保存到临时变量中(见下方右子树有副作用的情况)。
然而 \(s\) 与 \(e\) 是否 commute,在编译期并不总是能准确判断。例如:
x 和 z 是否指向同一地址?这依赖运行时信息,编译器无法确定。因此我们采取保守近似:
commute(s, e) = True仅当 \(s\) 和 \(e\) 确定可交换;commute(s, e) = False用于所有存疑的情况。
具体实现中,一个朴素(naive)的 commute 函数如下:
CONST(i)、NAME(n)与任何语句 commute(它们不访问任何临时变量或内存);- 空语句(如
EXP(CONST(0)))与任何表达式 commute; - 其余情况一律视为不 commute。
以下是各种具体例子:
-
左子树:
BINOP(op, ESEQ(s, e1), e2)\(\;\to\;\)ESEQ(s, BINOP(op, e1, e2)) -
右子树(\(s\) 与 \(e_1\) commute 时):
BINOP(op, e1, ESEQ(s, e2))\(\;\to\;\)ESEQ(s, BINOP(op, e1, e2)) -
右子树(\(s\) 与 \(e_1\) 不 commute 时):需要先将
e1保存到临时变量中:BINOP(op, e1, ESEQ(s, e2))\(\;\to\;\)ESEQ(MOVE(TEMP t, e1),\;ESEQ(s,\;BINOP(op, TEMP t, e2)))其中
t是一个新的临时变量。
-
左子树:
CJUMP(op, ESEQ(s, e1), e2, tr, fl)\(\;\to\;\)ESEQ(s, CJUMP(op, e1, e2, tr, fl)) -
右子树(\(s\) 与 \(e_1\) commute 时):
CJUMP(op, e1, ESEQ(s, e2), tr, fl)\(\;\to\;\)ESEQ(s, CJUMP(op, e1, e2, tr, fl)) -
右子树(\(s\) 与 \(e_1\) 不 commute 时):
CJUMP(op, e1, ESEQ(s, e2), tr, fl)\(\;\to\;\)ESEQ(MOVE(TEMP t, e1),\;ESEQ(s,\;CJUMP(op, TEMP t, e2, tr, fl)))
EXP(ESEQ(s, e))\(\;\to\;\)SEQ(s, EXP(e))
这里直接变成了 SEQ 而非 ESEQ,因为不再需要返回值。
ESEQ 消除的整体思路
消除 ESEQ 的整体思路可以归纳为两步:
- 子表达式提取 (subexpression-extraction):对当前结点的每个子结点,递归提取其中的「语句部分」得到一个纯语句 \(s_i\),并将子结点替换为其「ESEQ-clean 版本」\(e_i'\)。
- 子表达式回填 (subexpression-insertion):用清理后的 \(e_i'\) 重建当前结点,再根据 commute 关系将所有 \(s_i\) 组合成最终的
SEQ/ESEQ。
下面以一个具体例子走一遍这个过程。
CJUMP 中的 ESEQ 消除
原始 IR Tree:
Step 1 — 递归提取每个子表达式:
| 子表达式 | 提取结果 |
|---|---|
CONST(343) |
\(s_1 = \text{EXP}(\text{CONST}(0))\) (空语句),\(e_1' = \text{CONST}(343)\) |
MEM(ESEQ(s_x, TEMP a)) |
递归处理 → ESEQ(s_x, MEM(TEMP a)) → \(s_2 = s_x\),\(e_2' = \text{MEM}(\text{TEMP }a)\) |
此时左右子树分别更新为: - 左:\(\text{CONST}(343)\) - 右:\(\text{MEM}(\text{TEMP }a)\)
Step 2 — 回填并组合语句:
提取到的语句列表为 \([s_1, s_2]\),将其组合成 SEQ(s1, s2):
空语句 \(\text{EXP}(\text{CONST}(0))\) 没有实际效果,可以删掉,简化为 \(s_x\)。
最后判断是否需要 MOVE:\(s_2 = s_x\) 与 \(e_1' = \text{CONST}(343)\) 是否 commute?
— commute,因为常量不引用任何临时变量/内存,\(s_x\) 不可能影响 CONST(343)。因此不需要额外的 MOVE(TEMP t, ...)。
最终结果:
Call的副作用:¶
Tree 语言允许 CALL 节点作为子表达式出现,例如:
实际上的意思就是:
但是在真实约定中,每个函数调用的返回值通常都会放在同一个专门的返回值寄存器中,例如 a0。因此如果直接生成代码,可能出现如下求值顺序:
CALL(f, args1) // result in a0
CALL(g, args2) // overwrite a0
BINOP(PLUS, a0, a0) // both operands are now g's return value, not f's
此时第二个 CALL 会覆盖第一个 CALL 的返回值,导致 PLUS 无法得到正确的两个操作数。
CALL 作为子表达式的问题
CALL 不是普通的纯表达式:
-
它有副作用:会修改返回值寄存器
a0,也可能修改 caller-save 寄存器。 -
多个
CALL嵌套在同一个表达式中时,后一个调用可能覆盖前一个调用的返回值。
因此 canonical tree 要求:CALL 的父节点只能是 EXP(...) 或 MOVE(TEMP t, ...),不能直接出现在 BINOP、MEM、CJUMP 等表达式内部。
解决办法是:每次函数调用结束后,立刻把返回值保存到一个新的临时变量中。
变换规则如下:
转换为:
其中 t 是一个 fresh temporary。这个 ESEQ 的含义是:
- 先执行
MOVE(TEMP t, CALL(fun, args)),也就是调用函数并把返回值从TEMP(RV)保存到TEMP t。 - 再以
TEMP t作为整个表达式的值。
例如:
先改写为:
BINOP(
PLUS,
ESEQ(MOVE(TEMP t1, CALL(f, args1)), TEMP t1),
ESEQ(MOVE(TEMP t2, CALL(g, args2)), TEMP t2)
)
之后,ESEQ 消除器会把内部的 MOVE 逐步提升到外层,得到类似如下的规范化结果:
SEQ(
MOVE(TEMP t1, CALL(f, args1)),
SEQ(
MOVE(TEMP t2, CALL(g, args2)),
EXP(BINOP(PLUS, TEMP t1, TEMP t2))
)
)
再拆成 canonical trees 后,每个 CALL 都只出现在合法位置:
消除SEQ:¶
实际上,一堆嵌套的SEQ语句就是一个不断顺序执行的过程,因此我们要做的就是把如下左偏的SEQ树:
转换成右偏的SEQ树:
这样会更加直观,因为语句实际上就是:
到这里为止,我们已经知道了如何把一个任意的 IR Tree 转换成一个规范树了,接下来我们要做的就是把这些规范树划分成基本块,并且把这些基本块连接成轨迹了.
Basic Block
一个基本块是一堆语句,满足:
-
第一个语句是一个
LABEL作为整个基本块的唯一入口 -
最后一个语句是一个跳转指令,作为整个基本块的唯一出口
-
在基本块内部,没有任何
LABEL或跳转指令
要把一堆重整为规范树的语句变成一个个基本块,我们采取如下做法:
划分基本块¶
将一长串语句划分为基本块的算法如下:
-
从头到尾扫描整个语句序列。
-
每当遇到一个
LABEL,就开始一个新的基本块,同时结束前一个基本块。 -
每当遇到一个
JUMP或CJUMP,就结束当前基本块,并让下一条语句开始新的基本块。 -
如果某个基本块最后没有以
JUMP或CJUMP结尾,就在该基本块末尾补上一个跳转到下一个基本块标签的JUMP。 -
如果某个基本块开头没有
LABEL,就创建一个新的LABEL并插入到该基本块开头。
连接基本块成轨迹¶
基本块具有如下性质:一堆基本块可以以块为单位,按照任意顺序摆放,程序的输出是不变的.
那么,我们就可以调整基本块的顺序,从而实现我们在一开始说的:
真实机器的条件跳转指令在条件为假时是直通(fall-through)到下一条指令的
同时,我们也可以实现让所有无条件跳转的基本块的目标标签紧跟在它们后面,从而消去这些无条件跳转指令.
Trace
Trace 是一段语句序列,它们在程序执行过程中可能被连续执行,并且其中可以包含条件分支。
一个程序可以有很多不同的 trace,这些 trace 之间甚至可以相互重叠。
但是在重新排列 CJUMP 和 false-label 时,我们希望构造一组 trace,使其恰好覆盖整个程序:
- 每个基本块必须恰好属于一个 trace。
- 我们希望覆盖程序所需的 trace 数量尽可能少。
这样做的目的是:尽量减少从一个 trace 跳转到另一个 trace 时所需的 JUMP 数量。

Trace 连接算法示例
实际上,如果一个块是另一个块的Successor,实际上就是:
-
对于一个
CJUMP,如果它的两个Label对应的基本块都是它的 successor. -
对于一个
JUMP,如果它的目标标签是某个基本块的标签,那么这个基本块就是它的 successor。
上图已经展示了trace的构造方法,但是这个做法并不能保证CJUMP的false label紧跟在它后面,因此我们还需要对CJUMP做一些局部调整.
具体分三种情况:
-
如果某个
CJUMP后面已经紧跟它的 false label,则不需要修改。 -
如果某个
CJUMP后面紧跟的是它的 true label,则交换 true/false label,并对条件取反。改写为:
这样原来的 true label 变成了新
CJUMP的 false label,因此仍然满足“CJUMP后面紧跟 false label”的形式。 -
如果某个
CJUMP(cond, a, b, lt, lf)后面既不是lt,也不是lf,则新建一个 false labellf',并把单条CJUMP改写成三条语句:这样
CJUMP后面紧跟新建的 false labellf';如果条件为假,控制流先落到lf',再通过JUMP跳到原来的 false labellf。